
For Open Data Day, we organised an event to get together and take a dive into our repair data. On the day we focused specifically on data on computer repairs, as in the coming year there will be a revision of EU ecodesign regulation about computers, and therefore an opportunity to use insights from over 2,200 repairs of desktops, laptops and tablets to push for longer-lasting, repairable devices.
We had a great group of people join us, both existing Restarters and new volunteers from a data science background, who we’re very happy to have join the Restarters community!
Diving into the data

People worked on a range of problems through the day. Fitting with our Ecodesign theme, we were focusing on how the data that we collect on the problems and solutions for the computer repairs that we attempt can be categorised into specific fault and solution types. This data is currently recorded as free text, so a big part of the challenge (and the fun!) is the analysis of this text.
We had people working in Google Sheets, d3.js, Jupyter, and R. You can find the source for some of the things we worked on on the day in our data analytics Git repo.
Automated categorisation of fault types
@Lewis_Crouch worked on automated categorisation of faults using R. His workbook is here:
This started with a breakdown of the problem text into frequent terms:
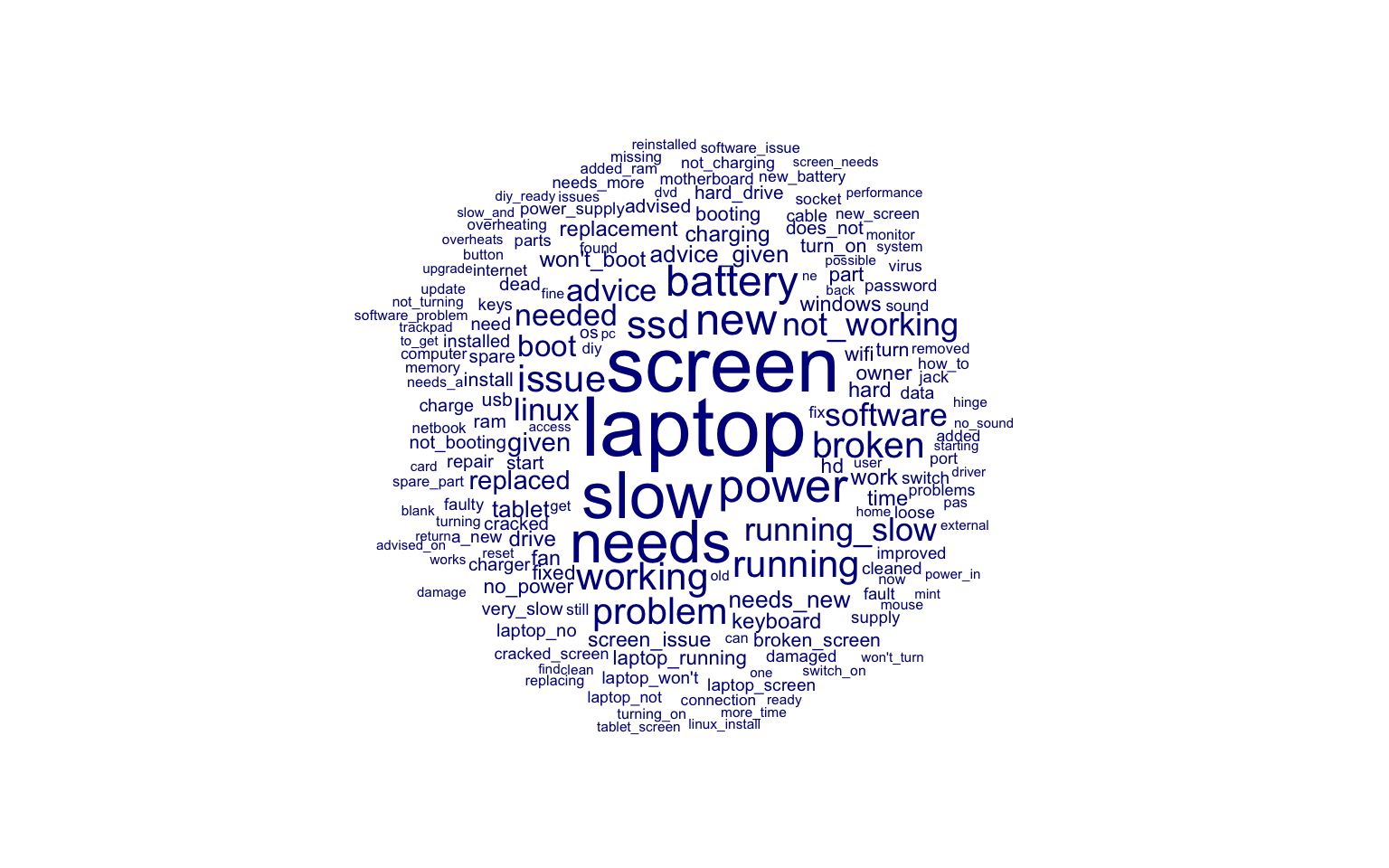
These were then grouped into keyword matches to categorise faults for each of the computer-related categories:
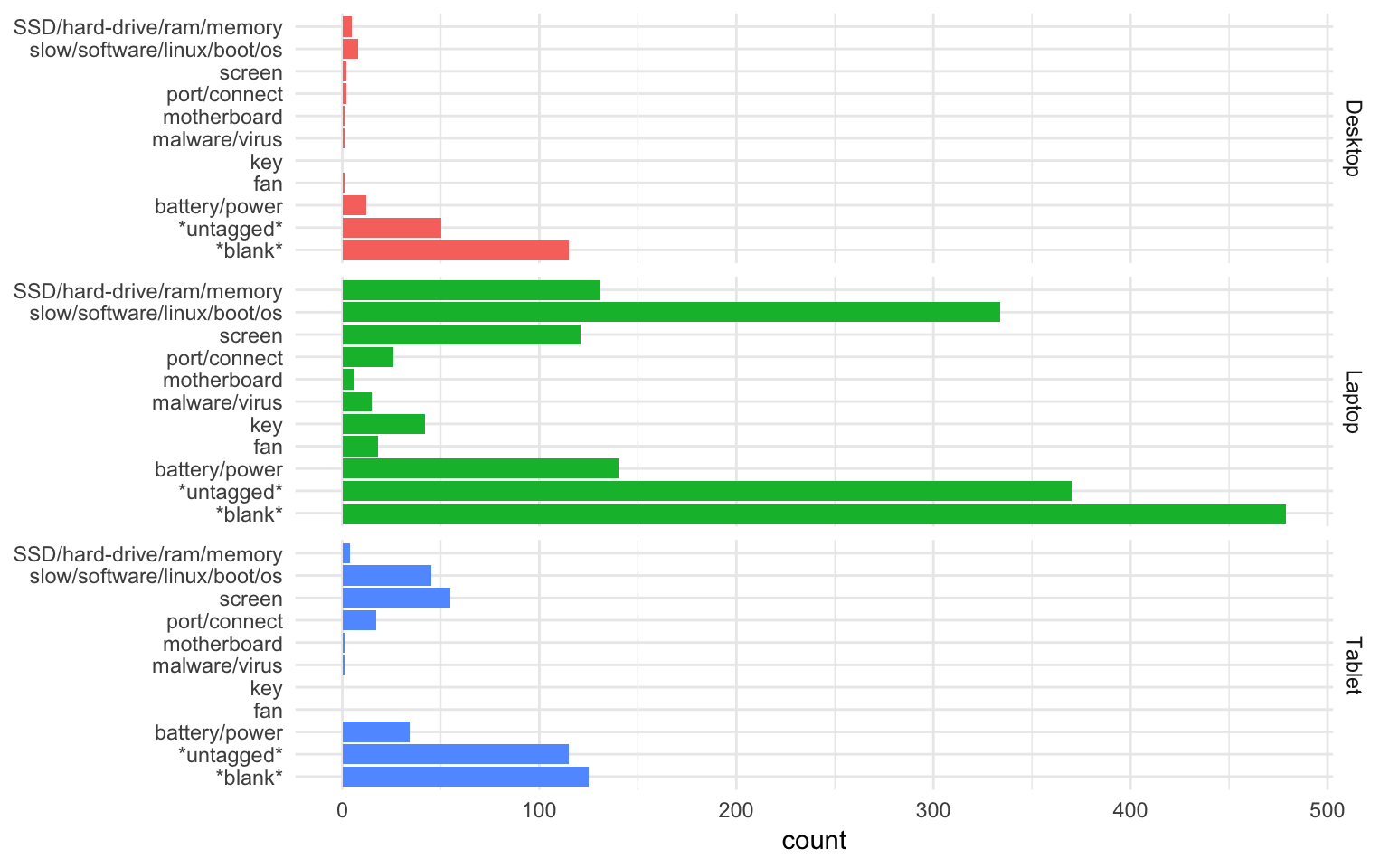
Along with giving an indication of which faults occur most frequently in the different types of devices (software issues and battery/power problems being indicated as most common in the laptop data looked at), we can see that that in many cases there is simply not enough information in the problem field to make a confident fault categorisation. This is an issue we are aware of and are actively exploring solutions to at the point of data capture - we could, for example, provide a drop-down of possible faults; and we are also looking at ways of spreading the load of data entry - by encouraging contributions from fixers at the event, or by having a dedicated ‘data volunteer’ who records information during the event live.
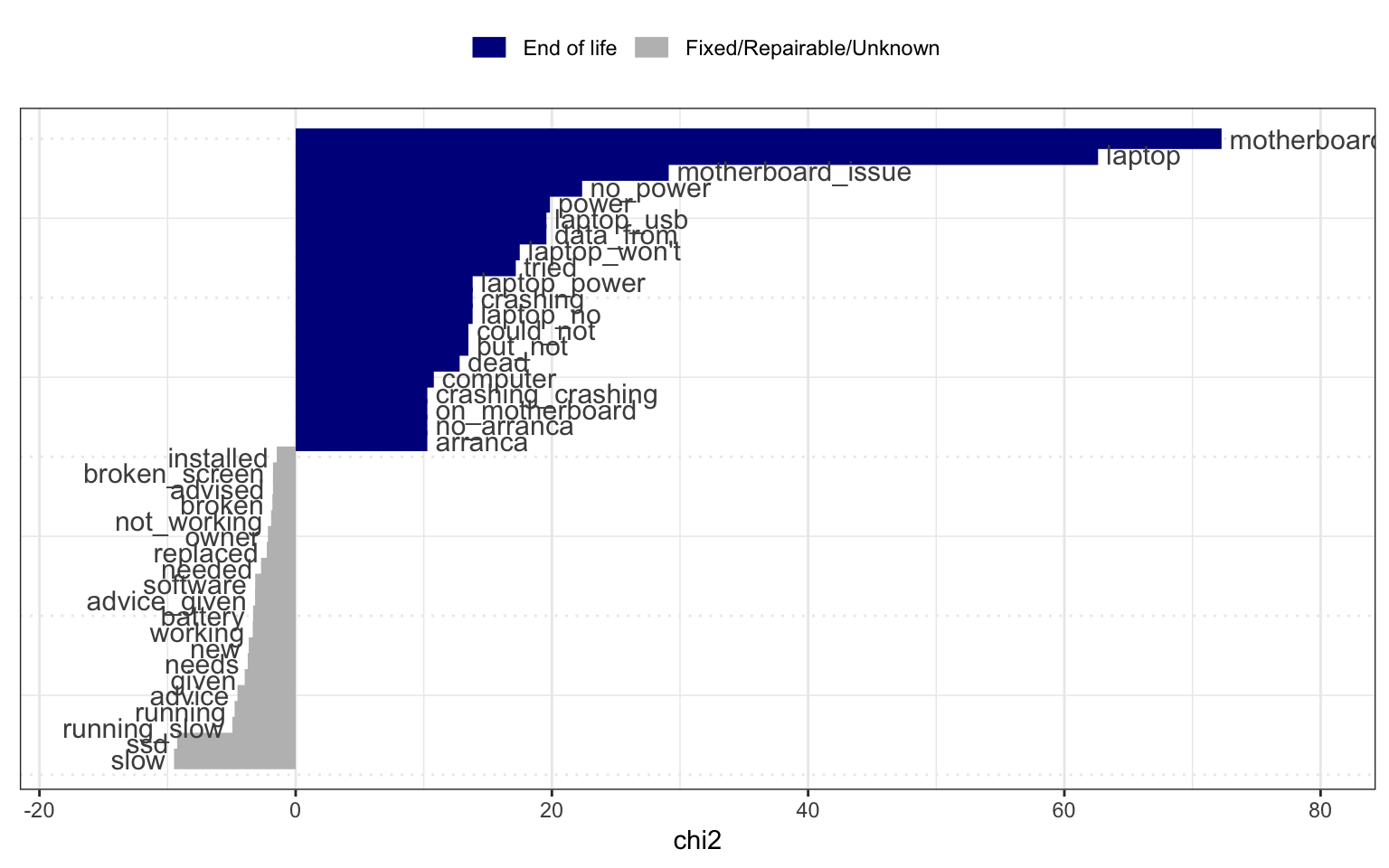
We are also interested in exploring how the fault encountered in a repair attempt correlates to the repair success. Some suggestions from the above diagram is that a motherboard fault correlates strongly with a fix being difficult, and that a computer running slowly is often easy to solve. We will explore this relationship further as we have more and better categorised data points on fault types.
Manual categorisation of fault types
We had also prepared a spreadsheet for manual categorisation of fault types - using people-powered crowdsourcing to classify the text. @Janet did a great job of categorising tablet faults through this method.
Once categorised, we were interested in knowing the breakdown of hardware vs software faults.
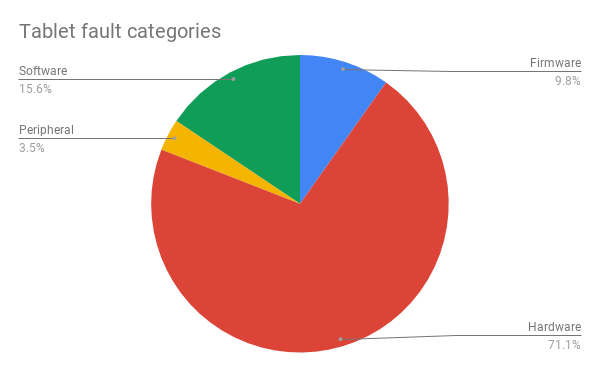
For the 173 tablet repairs we were able to categorise, the suggestion is that hardware faults are by far the most prevalent. (However, we noted that Unknown is again the majority of cases - so we need to improve data quality to allow us to make these statements with more accuracy).
Computers and repair outcomes
@Elena used Jupyter to produce a Sankey diagram of repair statuses for each of the categories of computers we were looking at:

We can see on the right-hand side that across all of these categories the most likely outcome is that they are fixed or repairable. On the left we can see that we see laptops and mobiles most frequently.
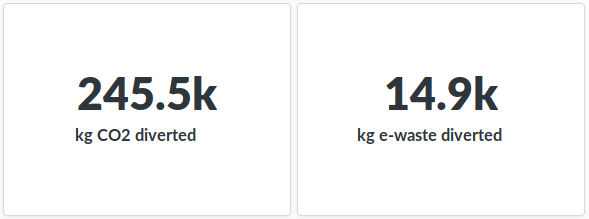
Impact analytics in Metabase
@Steve_Cook joined in Open Data Day remotely from the South London Maker Festival, where he was both fixing at our Restart Party on the day, and talking people through our impact data in our Metabase analytics tool.
Next steps
The data dive was a really instructive first pass at the task of categorising the data we’ve recorded on repair problems. It has helped us think through the questions we want to answer; to give a first indication of how to answer these questions; and to highlight where we can improve our data capture. We’ll be exploring all of these further in the coming months.
It’s been great to see just how interested our community is in repair data. Let’s keep the conversation going - please share any thoughts you might have about the data we looked at.